

Honey, I ate the HANA memory!
Maakt u zich geen zorgen. Deze blog gaat niet over de nieuwste Disney film, maar over een “side effect” waar wij onlangs tegenaan liepen in 1 van onze PMO scans. Nog even ter opfrissing: onze PMO scan helpt om uw HANA systeem in optimale conditie te krijgen en te houden. Meer details kunt u hier vinden.
Wat was het geval?
Onze klant gaf aan dat het HANA systeem op onverklaarbare wijze het volledig beschikbare geheugen alloceerde. Nu is HANA vaak hongerig op het gebied van geheugen, het verwerken van alle gegevens in geheugen is tenslotte 1 van de krachten van de database, maar dit was wel erg gortig.
1 van de zaken die ons opviel was dat een zogeheten “row store reorganisation” nodig was. U kunt deze actie vergelijken met de schijf defragmentatie die u vroeger weleens op uw laptop deed om alle data weer in de juiste volgorde te krijgen.
De HANA reorganisatie is een actie die voor optimaal resultaat, plaats moet vinden tijdens down time. Het is dus vaak zo dat dit niet frequent gebeurd, het down brengen van een systeem is tenslotte niet iets was altijd uitkomt.

- Restart time row store reorganization
Row store reorganization can be performed at restart time. Since there are no active update transactions during the restart time, this reorganization achieves the maximum compression ratio. - Online row store reorganization
Row store reorganization can be performed at runtime. To minimize the interference of other transactions, the relevant tables are locked exclusively and update transactions cannot be carried out on those tables. The list of affected tables is determined on the fly depending on the memory usage. As it is executed at runtime, some uncompressed row store memory may remain.
Mijn tip aan u is om frequent de Early Watch te raadplegen om te kijken of optimalisatie nodig is. Ga ook vooral voor de 1e optie voor maximaal resultaat.
Terugkomend op het probleem wat onze klant schetste, dit was nog niet het missende puzzelstukje.
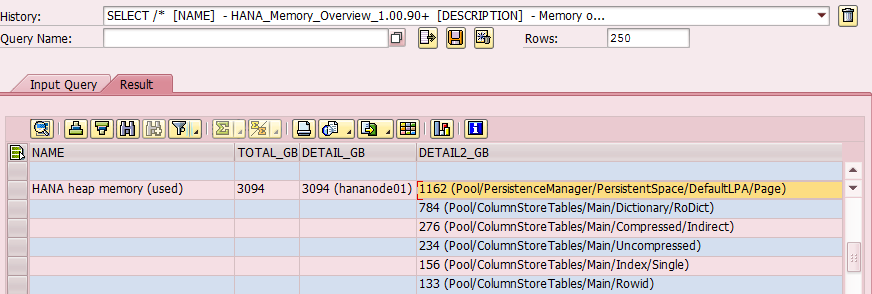
Wij vonden deze door een SQL statement te draaien waarin een grote geheugen allocatie aan het licht kwam:
Het geheugen in cache (database management in onderstaande illustratie) was net zo groot als alle data welke opgeslagen was in de DSOs en InfoObjecten (column tables)!
OSS Note 2301382 gaf ons een verklaring:
Starting with SAP HANA Rev. 110 some specific types of persistence pages (virtual file pages) are more likely to be added to the SAP HANA page cache to improve performance. As a result, once used, they will remain in memory, be counted as “Used memory”, and HANA will evict them only if the memory is needed for other objects, such as table data or query intermediate results.
On top of this behaviour a significant amount of pages can be cached unintentionally with SAP HANA Rev. 110 to 122.05 due to a problem in the SAP HANA software.
We zien hier een duidelijke bug (alinea 2), maar ook alinea 1 geeft wat vraagtekens. “evict only” geeft aan dat de cache voor lange tijd het geheugen bezet kan houden.
Indien we dit niet hadden gevonden tijdens onze PMO scan, had dit natuurlijk eenvoudig tot een onjuiste beslissing kunnen leiden. Het is voor systeembeheerders vaak lastig om aan te geven waarom het HANA systeem vol zit. Het wordt pas echt vervelend als alleen op basis van een algemene analyse van het geheugengebruik, besloten wordt om nieuwe hardware aan te schaffen, zonder diep het systeem in te duiken.
Onze klanten zien daar vaak de kracht van onze PMO scan, wij gaan door tot het laatste puzzelstukje gevonden is!
SAP heeft overigens actie ondernomen om de honger van het HANA systeem te stillen. In Note 2403124 wordt beschreven hoe door het zetten van een parameter men weer terug kan naar de situatie voor SPS11.
Eind goed al goed!