

Using the new selective deletion functionality in SAP Datasphere to track record deletion in the source (part 2)
In my first blog post on this topic I already introduced you to the new selective deletion functionality in SAP Datasphere. In this second blog post I will show you how you can track record deletion in the source.
So below you will see the scenario that we are going to build through this blog.
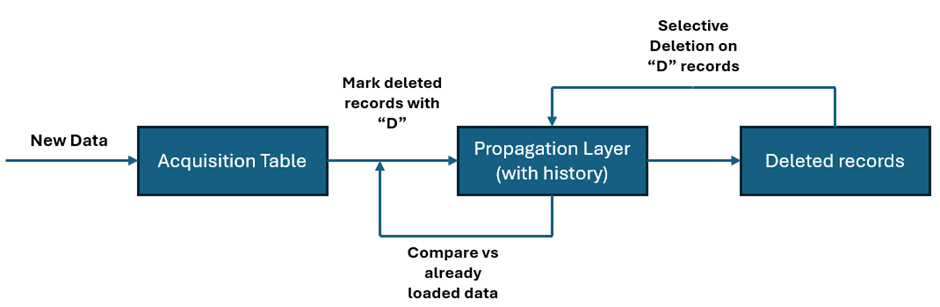
For this example I have a simple flatfile that contains some data about the job security related to the upcoming of AI (you can download this data from Kaggle). It contains data on job titles, industry, company size, etc. Let’s pretend that this dataset only delivers us the data for the latest month constantly and we know records do get deleted in the source. The business requirement is however to build up a history over time and for that we obviously need to get rid of the deleted records in the source in our “trend”-table.
We start by loading this file into SAP Datasphere via a simple dataflow, into our acquisition table, making sure that the dataflow will truncate the inbound table upon loading. This table now always represents the latest data that was present in the file at runtime.
We also need our “trend”-table, in this table we obviously need to make sure that we define our key correctly so we can use the update feature in the dataflow.
So now comes the trickier part: how do we know if the data that comes from the file was already sitting in our “trend”-table? This is where we are going to use the logic of joins! If a record no longer appears in the file, while it is present in the “trend”-table it apparently was deleted from the source.

In the deleted records part I have added a column Existing in the data that is coming from the new table. When joining this on the trend data we expect that to be NULL for the records that were deleted from the source. We then manipulate the record status to ‘D’ in the last Calculated Column node and Union those records to all the records coming from the file.
See it in action:
So the first time we load everything that is coming will come through the top part of the data flow:

We can see from the data preview that we will load 471 records.
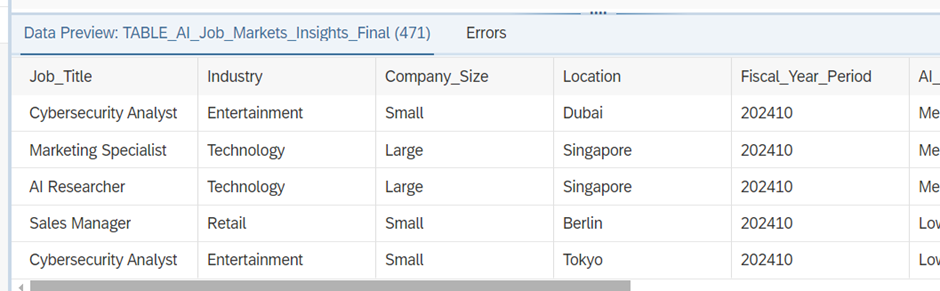
Now we upload the same file, but we delete quite a lot of records from the file (143 to be exact). So, we expect that 143 records will show as Existing = NULL and Record Status = D.
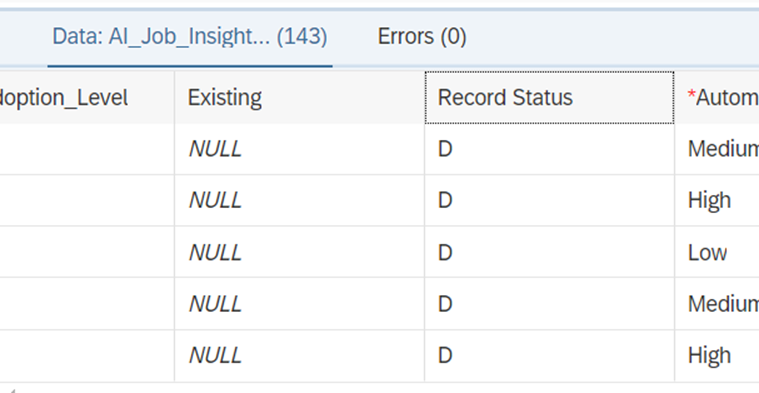
When loading this data to the “trend”-table we still have 471 records, of which 143 are now marked with Record Status = ‘D’.
Keep in mind that you only want to compare the current month with the incoming data, otherwise everything will be marked as deleted 😉. For this I have added that filter node on the period table:

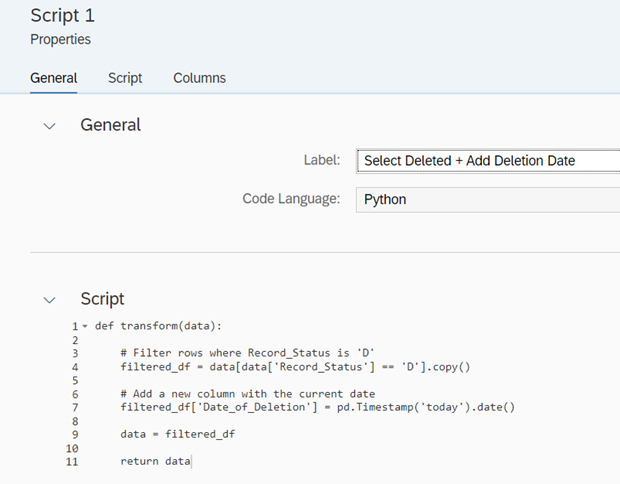
With a simple dataflow we can load now the records that were marked for deletion into a new table, so we could report on it later, or use it for audit purposes. We can either use a new graphical view to load that data or use some Python in the dataflow. I have added an extra column with the date of deletion, so it is easier to find the log in the future.
Now that we have the deleted records sitting in a new table we can go ahead and make sure these records get deleted from the “trend”-table. For this we will now manually use the selective deletion function, but of course we could also make a schedule to this.
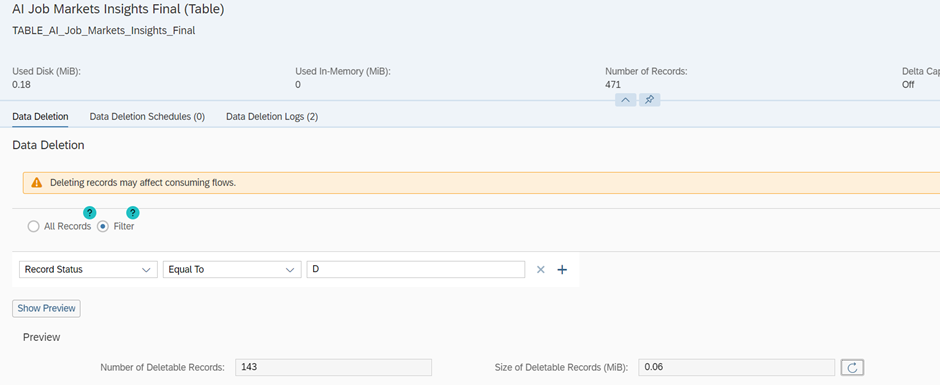
Unfortunately, since the functionality to plan a selective deletion in a task chain is not (yet) available, we must think of some smart planning to get the separate components aligned, and we do have a few risks, but it is what it is at the moment.
Conclusion
In conclusion, leveraging the new selective deletion functionality in SAP Datasphere offers a powerful method to manage and track record deletions in the source system. By carefully constructing a dataflow with the right logic, we can maintain a historical view in the “trend”-table while ensuring that deleted records are appropriately flagged. This method enables accurate auditing and reporting of deleted records by storing them separately for future reference. Although the current limitations around scheduling selective deletions require some manual intervention, this approach provides an effective workaround until full automation is supported.