

Het Interdobs Webflix SQL Data Warehouse, deep dive: het laden van data – deel 2
Zoals ik u beloofde in deel 1 van mijn blog, wil ik u graag meenemen in de verschillende componenten van ons Interdobs SQL Data Warehouse. Ter opfrissing: het fictieve bedrijf “WebFlix” moet digitaliseren en zit midden in haar transitie van de oude wereld (DVD verkopen en verhuur) naar de nieuwe streaming wereld. Zij heeft onlangs besloten om de “digital core” van SAP te implementeren met S/4HANA, het HANA SQL Data Warehouse en SAP Data Hub.
Ons SQL Data Warehouse zit vol met innovaties. Vandaag zal ik u meenemen in de opslag en modellering van de diverse objecten. De rapportage kant via Calculation views en SAP Analytics Cloud zal ik behandelen in het derde deel van deze serie.
Het voorwerk
Om te kunnen beginnen met een SQL Data Warehouse moet de data warehouse foundation geïnstalleerd worden via XSA. Deze plug-in zorgt ervoor dat er diverse componenten beschikbaar komen waarmee stapsgewijs het data warehouse opgebouwd kan worden. De stappen worden beschreven op de volgende pagina.
Vervolgens maken wij gebruik van SDI om een koppeling te leggen met onze SQL database. Dit doen we aan de HANA kant zodat we deze later aan onze HDI container kunnen koppelen.
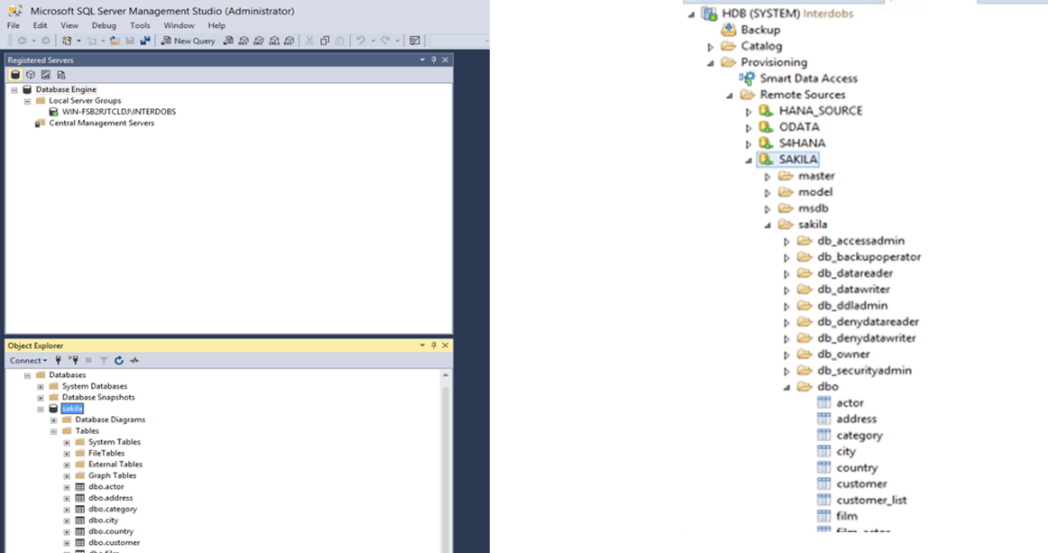
Overigens is een HDI container een bijzonder object in het SQL DWH. Het is een afgeschermd, geïsoleerd gebied met een eigen namespace en schema’s welke de objecten bevat van het DWH.
Het DWH project
Na het voorwerk kan er definitief gestart worden met het inrichten van het data warehouse. Hiervoor moet er een nieuw project aangemaakt worden via de SAP Web IDE.
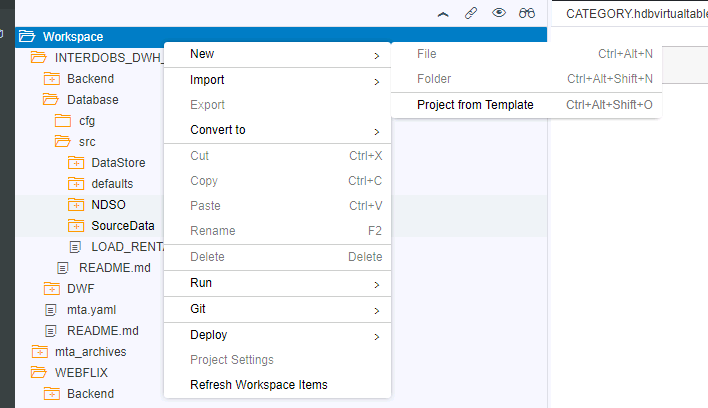
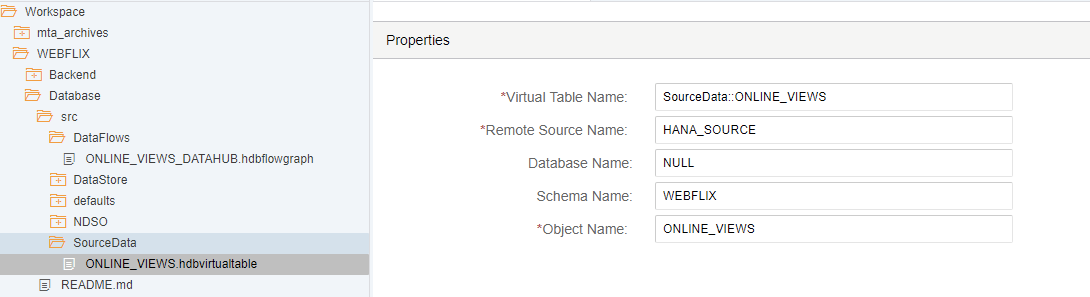
Binnen dit project kunnen de diverse objecten aangemaakt worden te beginnen met onze bron: de virtuele tabellen.
Overigens moet er voordat de HDI container contact kan maken met de tabel, wel de rechten goed staan. Er moeten aan de HANA database kant rechten gegeven worden op de gegenereerde HDI user (PROJECT_NAME * _CONTAINER_1_#OO ). Een stap die eenvoudig over het hoofd gezien kan worden.
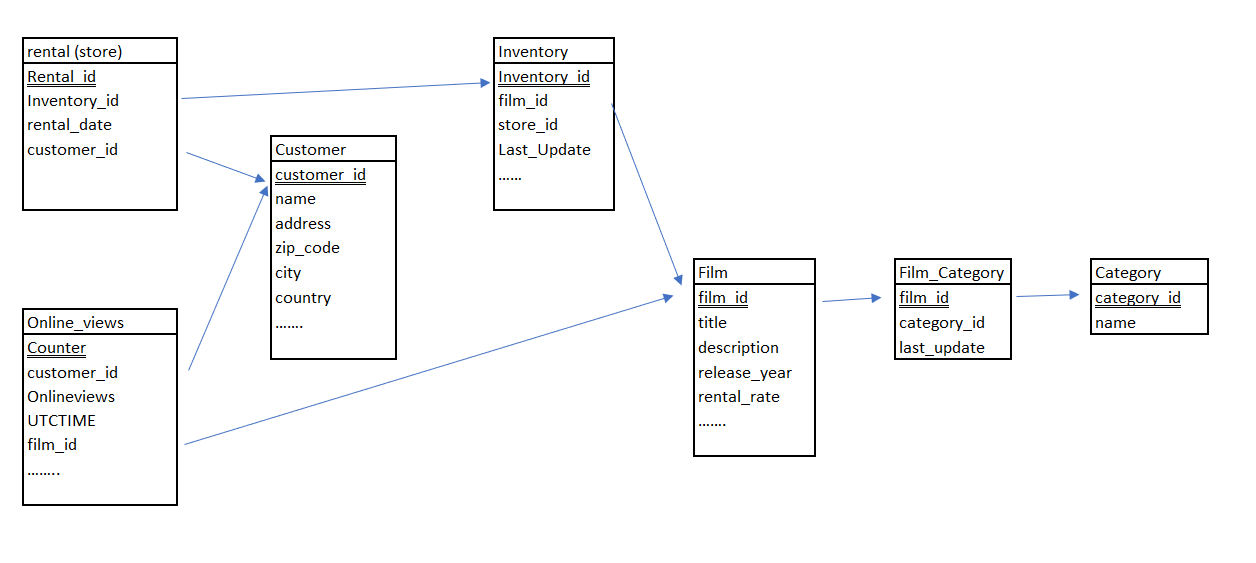
Voor ons SQL DWH maken we de volgende tabellen aan:
Deze koppelen we vervolgens via FlowGraphs (persistent) en (uiteindelijk) via Calculation Views aan elkaar.
Het laden van “Rentals” naar een HANA tabel
We beginnen met het laden van de “Rentals” records uit onze SQL database.
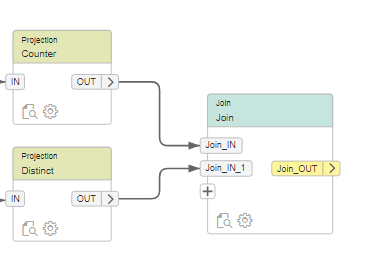
Om te kunnen bepalen hoe succesvol onze rental business nog is, maken we een counter aan door middel van een projection.
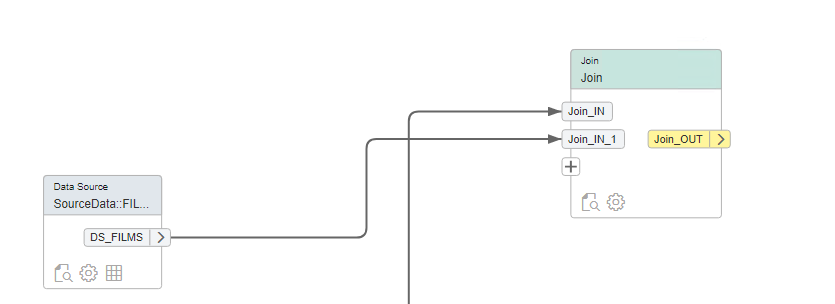
Vervolgens joinen we deze met de unieke (film) records uit onze “inventory” tabel. We gebruiken hiervoor een distinct optie om de unieke film Ids te krijgen.
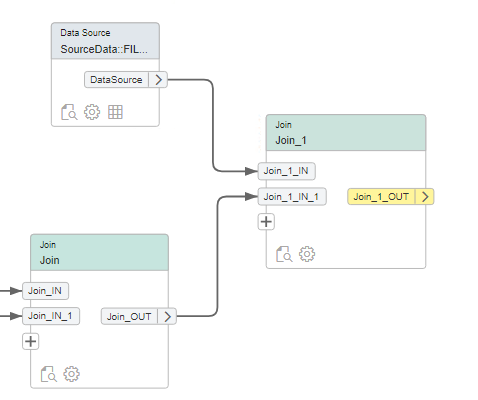
Vervolgens hebben we ook nog een prijs nodig, ook deze koppelen we aan onze FlowGraph
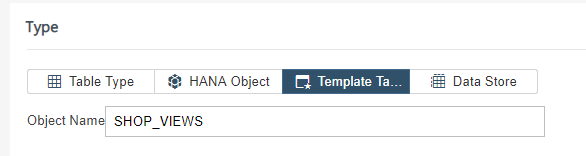
Als laatst stap kunnen we de data naar een nieuwe tabel laden: SHOP_VIEWS
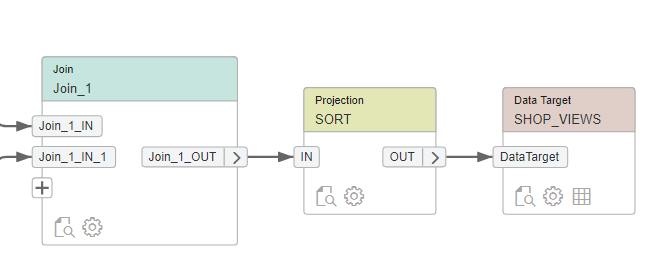
Na de build fase en uitvoer stap, kan er door middel van preview gekeken worden naar de resultaten
![]()
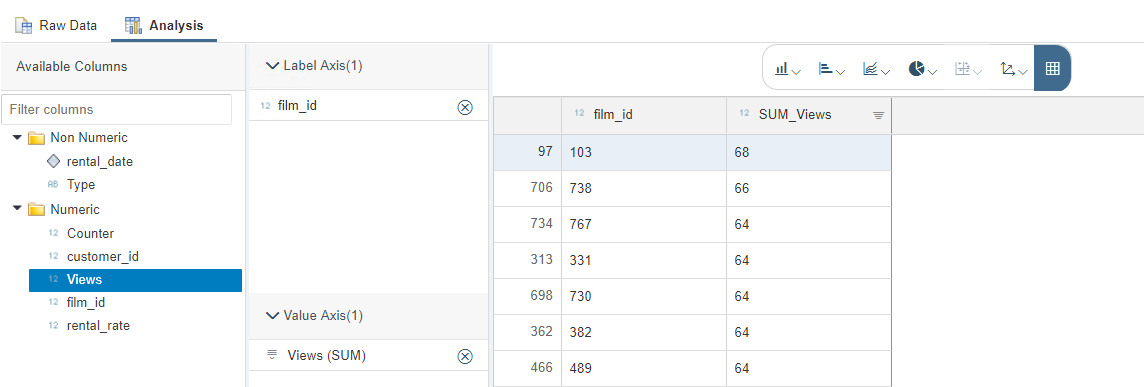
We hebben een eerste data flow gemaakt tussen SQL en HANA!
Het laden naar een NDSO
Naast onze klassieke wereld (het verhuren van films), heeft WebFlix natuurlijk ook haar nieuwe streaming wereld. Omdat deze streams constant worden doorgegeven aan onze HANA database, moeten we voor de verdere staging een delta gaan bepalen. Hiervoor gebruiken we de NDSO.
Een Native Data Store object heeft soortgelijke kenmerken als de Advanced DSO zoals we deze kennen in BW/4HANA. Belangrijke eigenschappen zijn natuurlijk het kunnen bepalen van delta records en het her-construeren na bijvoorbeeld een foutieve data load. Ook de NDSO wordt via de Web IDE aangemaakt
Aanmaken DSO
De juiste sleutel
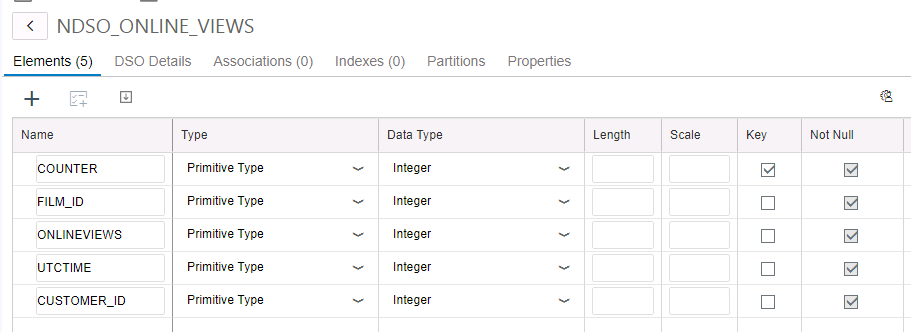
Na het genereren van de NDSO kan de data flow aangemaakt worden.
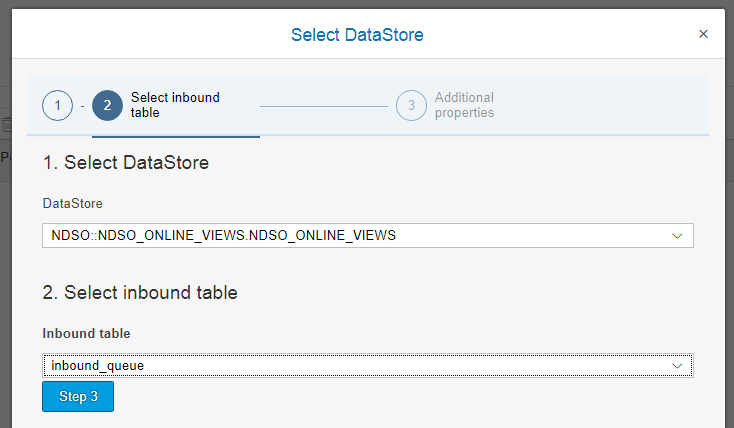
De gegenereerde data flow bepaald zelf de relaties tussen de inbound en outbound queues voor de delta’s!
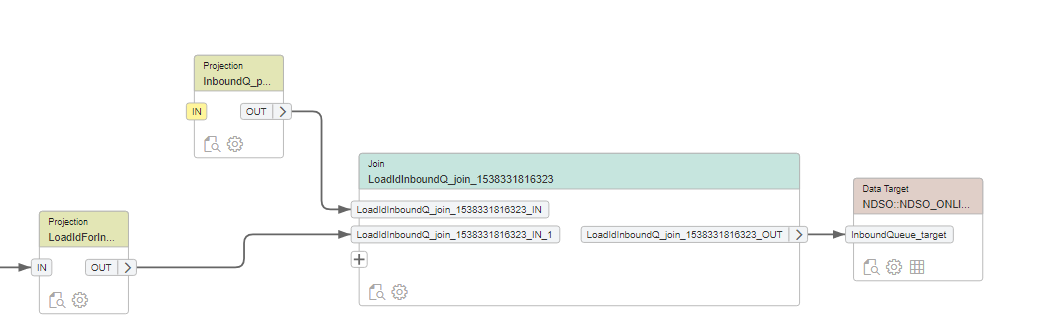
Voordat we data kunnen laden, koppelen we de streams uit SAP DataHub aan onze flow
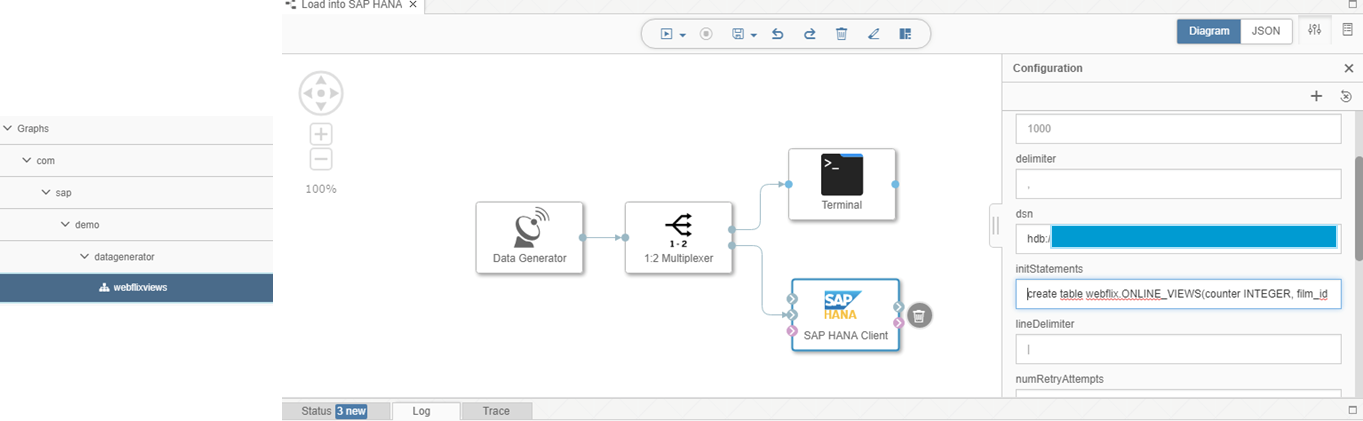
Via DataHub worden om de 5 seconden nieuwe records doorgegeven met daarin een counter als uniek ID van de transactie, film_id’s en customer_id’s, een indicator voor de dag en een teller (1). De resultaten staan in tabel ONLINE_VIEWS in schema WEBFLIX. Deze tabel wordt natuurlijk voor tracking en tracing doeleinden niet geleegd!
Door middel van een full load wordt de data uit tabel ONLINE_VIEWS naar de NDSO geschreven. In deze NDSO wordt daarom een delta bepaald. Deze delta records worden vervolgens doorgeladen naar een target tabel ONLINE_VIEWS_CONS. Onderweg worden transformaties op de data worden.
Bron tabel:
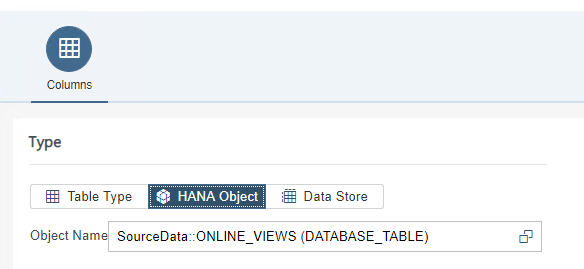
Bron richting InboundQ
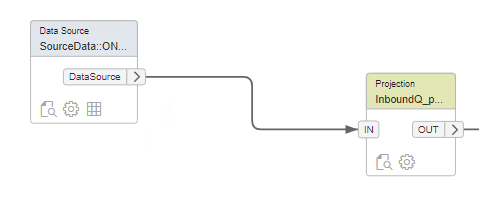
Als laatste stap willen we onze records gaan verrijken via projections. Er zijn ook in het SQL data warehouse vele mogelijkheden om data te verrijken. Van eenvoudige formules tot stored procedures en functions.
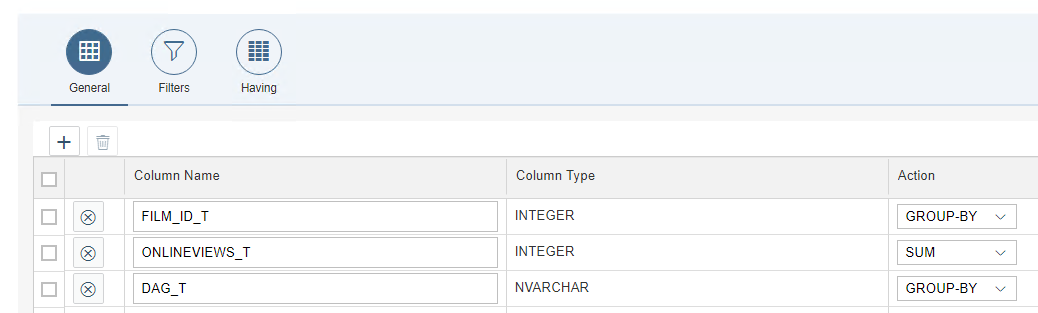
We beginnen met het bepalen van de dag uit de timestamp.

Ook moeten we een teller en een noemer gaan berekenen.
En vervolgens mappen we deze aan elkaar door de aggregation nodes en aangemaakte node te koppelen
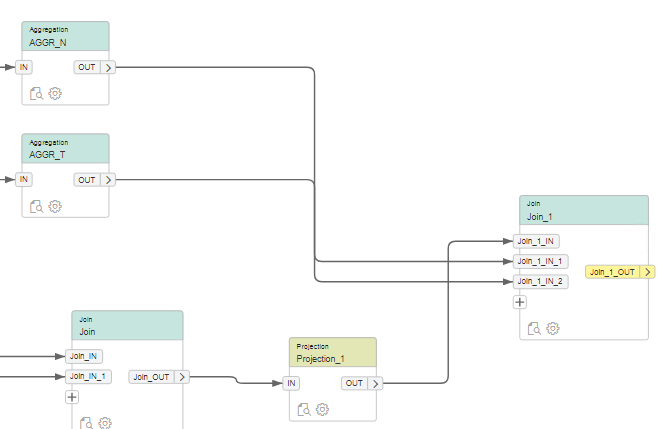

We berekenen een teller (aantal views per film per dag) en een noemer (aantal online views per dag) om een ratio te kunnen berekenen op de online prijs van onze views. Zo kunnen we dynamisch de prijs bepalen op basis van vraag en aanbod i.p.v. een vaste prijs zoals WebFlix deed in de oude economie (verhuren van fysieke films). Hoe we dit doen leg ik uit in een volgend blog. De berekening vindt in ieder geval plaats in de Calculation view: (rate * (1 + Num / Denom).
De TaskChain
Als laatste wil ik u nog even meenemen in het laadproces. Ook hier heeft de Data Warehouse Foundation een antwoord op in de vorm van een TaskChain. En ook zoals de Process Chain bij grote broer BW/4HANA kan deze natuurlijk gescheduled worden.
Laden NDSO flowgraph
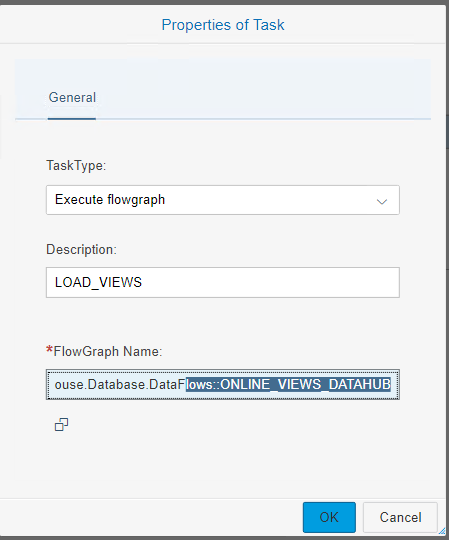
En natuurlijk het activeren van de NDSO data
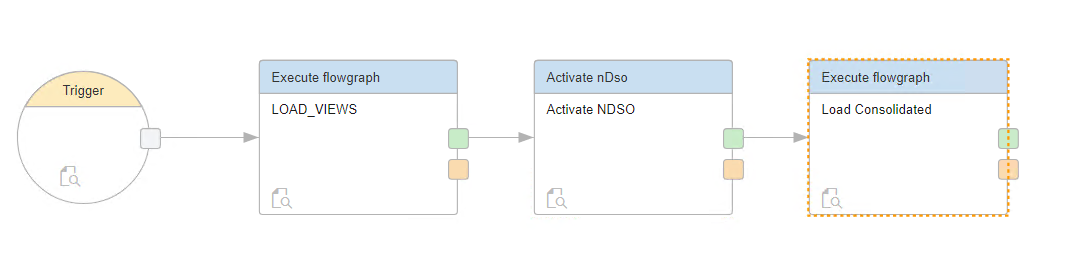
Vervolgens kan via de monitor de data load verder uitgevoerd en gemonitord worden!
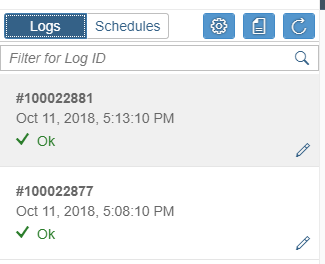
In onze laatste blog zal ik de koppeling met Github verder toelichten.
Fijn sitNL weekend namens het Interdobs SQL DWH team!
Ronald Konijnenburg
Frans van der Peijl
Tim Koster